COMANDOS
.- IPCONFIG /ALL: Mostrar configuración de las conexiones de red
.- IPCONFIG /DISPLAYDNS: Mostrar configuración sobre las DSN de la red
.- IPCONFIG /FLUSHDNS: Borrar la caché de las DNS en la red
.- IPCONFIG /RELEASE: Borrar la IP de todas las conexiones de red
.- IPCONFIG /RENEW: Renovar la IP de todas las conexiones de red
.- IPCONFIG /REGISTERDNS: Refrescar DHCP y registrar de nuevo las DNS
.- IPCONFIG /SHOWCLASSID: Mostrar información de la clase DCHP
.- IPCONFIG /SETCLASSID :Cambiar/modificar el ID de la clase DHCP
.- CONTROL NETCONNECTIONS: Conexiones de red
.- NETSETUP.CPL: Asistente de conexión de red
.- PING DOMINIO.TLD: Comprobar conectividad: (ejemplo: ping andy21.com)
.- TRACERT :Tracear la ruta de una dirección IP
.- NETSTAT :Mostrar la sessión del protocolo TCP/IP
.- ROUTE: Mostrar la ruta local
.- ARP Mostrar la dirección MAC
.- HOSTNAME: Mostrar el nombre de la computadora
Comandos TCP-IP para Windows
A veces es necesario conocer los comandos IP, para analizar e incluso configurar nuestra red TCP/IP.
A continuación una lista de comandos a utilizar en una ventana DOS:
•PING
•TRACERT
•IPCONFIG
•NETSTAT
•ROUTE
•ARP
•NBTSTAT
•TELNET
•HOSTNAME
•FTP
PING
Comandos para Simbolo del Sistema[/align]]
PING: Diagnostica la conexión entre la red y una dirección IP remota
ping -t [IP o host]
ping -l 1024 [IP o host]
•La opción –t permite hacer pings de manera continua, para detenerlo pulsar Ctrl-C.
Este comando también es útil para generar una carga de red, especificando el tamaño del paquete con la opción –l y el tamaño del paquete en bytes.
TRACERT
TRACERT: Muestra todas las direcciones IP intermedias por las que pasa un paquete entre el equipo local y la dirección IP especificada.
tracert [@IP o nombre del host]
tracert -d [@IP o nombre del host]
Este comando es útil si el comando ping no da respuesta, para establecer cual es el grado de debilidad de la conexión.
IPCONFIG
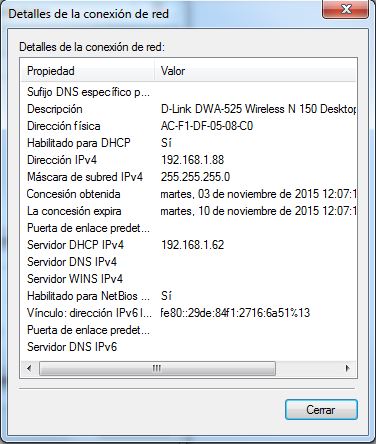
IPCONFIG: Muestra o actualiza la configuración de red TCP/IP
ipconfig /all [/release (tarjeta)] [/renew (tarjeta)] /flushdns /displaydns /
registerdns [-a] [-a] [-a]
Este comando ejecutado sin ninguna opción, muestra la dirección IP activa, la máscara de red así como la puerta de enlace predeterminada al nivel de las interfaces de red conocidas en el equipo local.
•/all: Muestra toda la configuración de la red, incluyendo los servidores DNS, WINS, bail DHCP, etc ...
•/renew (tarjeta) : Renueva la configuración DHCP de todas las tarjetas (si ninguna tarjeta es especificada) o de una tarjeta específica si utiliza el parámetro tarjeta. El nombre de la tarjeta, es el que aparece con ipconfig sin parámetros.
•/release (tarjeta): Envía un mensaje DHCPRELEASE al servidor DHCP para liberar la configuración DHCP actual y anular la configuración IP de todas las tarjetas (si ninguna tarjeta es especificada), o de sólo una tarjeta específica si utiliza el parámetro tarjeta. Este parámetro desactiva el TCP/IP de las tarjetas configuradas a fin de obtener automáticamente una dirección IP.
•/flushdns: Vacía y reinicializa el caché de resolución del cliente DNS. Esta opción es útil para excluir las entradas de caché negativas así como todas las otras entradas agregadas de manera dinámica.
•/displaydns: Muestra el caché de resolución del cliente DNS, que incluye las entradas pre cargadas desde el archivo de host local así como todos los registros de recursos recientemente obtenidos por las peticiones de nombres resueltas por el ordenador. El servicio Cliente DNS utiliza esta información para resolver rápidamente los nombres frecuentemente solicitados, antes de interrogar a sus servidores DNS configurados.
•/registerdns: Actualiza todas las concesiones DHCP y vuelve a registrar los nombres DNS.
NETSTAT
informacion
NETSTAT: Muestra el estado de la pila TCP/IP en el equipo local
NETSTAT [-a] [-e] [-n] [-s] [-p proto] [-r] (intervalo)
•-a Muestra todas las conexiones y puertos de escucha. (Normalmente las conexiones del lado del servidor no se muestran).
•-e Muestra estadísticas Ethernet. Se puede combinar con la opción –s.
•-n Muestra direcciones y números de puerto en formato numérico.
•-p proto Muestra las conexiones del protocolo especificado por proto; proto puede ser tcp o udp. Utilizada con la opción –s para mostrar estadísticas por protocolo, proto puede ser tcp, udp, o ip.
•-r Muestra el contenido de la tabla de rutas.
•-s Muestra estadísticas por protocolo. Por defecto, se muestran las estadísticas para TCP, UDP e IP; la opción –p puede ser utilizada para especificar un sub conjunto de los valores por defecto.
•intervalo Vuelve a mostrar las estadísticas seleccionadas, con una pausa de “intervalo” segundos entre cada muestra.
Presiona Ctrl+C para detener la presentación de las estadísticas.
ROUTE
ROUTE: Muestra o modifica la tabla de enrutamiento
ROUTE [-f] [comando (destino) [MASK mascara de red] [puerto de enlace]
•-f Borra de las tablas de enrutamiento todas las entradas de las puertas de enlace. Utilizada conjuntamente con otro comando, las tablas son borradas antes de la ejecución del comando.
•-p Vuelve persistente la entrada en la tabla después de reiniciar el equipo.
•comando especifica uno de los cuatro comandos siguientes:
oDELETE: borra una ruta.
oPRINT: Muestra una ruta.
oADD: Agrega una ruta.
oCHANGE: Modifica una ruta existente.
•destino: Especifica el host.
•MASK: Si la clave MASK está presente, el parámetro que sigue es interpretado como el parámetro de la máscara de red.
•máscara de red: Si se proporciona, especifica el valor de máscara de subred asociado con esta ruta. Si no es así, éste toma el valor por defecto de 255.255.255.255.
•puerta de enlace: Especifica la puerta de enlace.
•METRIC: Especifica el coste métrico para el destino.
ARP
ARP: Resolución de direcciones IP en direcciones MAC. Muestra y modifica las tablas de traducción de direcciones IP a direcciones Físicas utilizadas por el protocolo de resolución de dirección (ARP).
ARP -s adr_inet adr_eth [adr_if]
ARP -d adr_inet [adr_if]
ARP -a [adr_inet] [-N adr_if]
•-a Muestra las entradas ARP activas interrogando al protocolo de datos activos. Si adr_inet es precisado, únicamente las direcciones IP y Físicas del ordenador especificado son mostrados. Si más de una interfaz de red utiliza ARP, las entradas de cada tabla ARP son mostradas.
•-g Idéntico a –a.
•adr_inet Especifica una dirección Internet.
•-N adr_if Muestra las entradas ARP para la interfaz de red especificada por adr_if.
•-d Borra al host especificado por adr_inet.
•-s Agrega al host y relaciona la dirección Internet adr_inet a la Física adr_eth. La dirección Física está dada bajo la forma de 6 bytes en hexadecimal separados por guiones. La entrada es permanente.
•adr_eth Especifica una dirección física.
•adr_if Precisado, especifica la dirección Internet de la interfaz cuya tabla de traducción de direcciones debería ser modificada. No precisada, la primera interfaz aplicable será utilizada.
NBTSTAT
NBTSTAT : Actualización del caché del archivo Lmhosts. Muestra estadísticas del protocolo y las conexiones TCP/IP actuales utilizando NBT (NetBIOS en TCP/IP).
NBTSTAT [-a Nom Remoto] [-A dirección IP] [-c] [-n] [-r] [-R] [-s] (intervalo)
•-a (estado de la tarjeta) Lista la tabla de nombres del equipo remoto (nombre conocido).
•-A (estado de la tarjeta) Lista la tabla de nombres del equipo remoto (dirección IP)
•-c (caché) Lista el caché de nombres remotos incluyendo las direcciones IP.
•-n (nombres) Lista los nombres NetBIOS locales.
•-r (resueltos) Lista de nombres resueltos por difusión y vía WINS.
•-R (recarga) Purga y recarga la tabla del caché de nombres remotos.
•-S (sesión) Lista la tabla de sesiones con las direcciones de destino IP.
•-s (sesión) Lista la tabla de sesiones establecidas convirtiendo las direcciones de destino IP en nombres de host a través del archivo host.
Un ejemplo:
nbtstat -A @IP
Este comando devuelve el nombre NetBIOS, nombre del sistema, los usuarios conectados…del equipo remoto.
TELNET
TELNET
telnet <IP o host>
telnet <IP o host> <port TCP>
El comando telnet permite acceder en modo Terminal (Pantalla pasiva) a un host remoto. Este también permite ver si un cualquier servicio TCP funciona en un servidor remoto especificando después de la dirección IP el número de puerto TCP.
De este modo podemos verificar si el servicio SMTP, por ejemplo, funciona en un servidor Microsoft Exchange, utilizando la dirección IP del conector SMTP y luego 25 como número de puerto. Los puertos más comunes son:
•ftp (21),
•telnet (23),
•smtp (25),
•www (80),
•kerberos (88),
•pop3 (110),
•nntp (119)
•et nbt (137-139).
HOSTNAME
HOSTNAME: Muestra el nombre del equipo
FTP
FTP: Cliente de descarga de archivos
ftp –s:<file>
•-s : esta opción permite ejecutar un FTP en modo batch: especifica un archivo textual conteniendo los comandos FTP.
•--------------------------------------------------------------------------------------
COMANDO PING (PING COMMAND)
redes
Qué es el comando PING (PING Commands)
Hacer un PING un equipo o una IP. significa ejecutar el comando PING. Este comando lo que hace es enviar a ese equipo o dirección una serie de paquetes de datos de un tamaño total de 64 bytes y luego espera el retorno de esos paquetes de datos (eco). Este comando es utilizado para medir el tiempo (o la latencia) que demoran en comunicarse dos puntos remotos.
Porque es útil el Comando PING ?
Porque los paquetes de datos se envían directamente al equipo o a la IP adonde enviamos el ping.
Como comprobar el funcionamiento de nuestra RED
Para comprobar el funcionamiento de los equipos en nuestra red debemos hacer tres Comandos PING en el siguiente orden:
1. Un Comando PING a nuestra IP local
=> Ejemplo: PING 192.168.1.15
Con esto comprobamos que nuestra tarjeta de red se encuentra funcionando correctamente
2. Un Comando PING (PING Command) a nuestro Gateway (o Puerta de Enlace)
=> Ejemplo: PING 192.168.1.1
Con esto comprobamos que nuestro equipo se comunica correctamente con nuestro router
3. Un Comando PING (PING Command) a nuestro servidor DNS
=> Ejemplo: PING 200.123.180.41
Con esto comprobamos que nuestro equipo se comunica correctamente con el exterior (Internet)
Como chequear equipos dentro de nuestra red
Para comprobar que los equipos que están conectados en nuestra red podemos enviar un PING también. Por lo que si tenemos un equipo conectado a una IP determinada y queremos saber si el equipo esta conectado correctamente entonces podemos enviar un PING a su IP.
PING Online
También podemos hacer un ping una dirección en Internet. Por ejemplo, podemos hacer ping www.yahoo.com
Modificadores del comando PING para windows
El comando PING posee varios modificadores que podemos utilizar para ampliar la información que recibimos. Estos modificadores son:
-t
Hacer ping al host especificado hasta que se detenga
-a
Resolver direcciones en nombres de host
-n cuenta
Número de solicitudes de eco para enviar
-l tamaño
Enviar tamaño del búfer
-i TTL
Tiempo de vida (Time To Live)
-v TOS
Tipo de servicio, sólo en IPv4 (Time Of Service)
-w tiempo de espera
Tiempo de espera en milisegundos para esperar cada respuesta.
Saludos!!!